Abstraction and Limiting Information Flow
Do you recognize this pattern?
let DATABASE_URL;
if (process.env.NODE_ENV === 'production') {
DATABASE_URL='postgres://anarchist-wombat.myhostedpostgresservice.com/production';
}
else if (process.env.NODE_ENV === 'test') {
DATABASE_URL='postgres://anarchist-wombat.myhostedpostgresservice.com/staging';
}
else {
DATABASE_URL='postgres://127.0.0.1:5432/mylocaldb';
}We're consulting a list of known environment names in order to decide which database url to connect to. The specific variable name DATABASE_URL isn't important. We could be talking about an API_URL or a logging strategy. This code could be client side or server side. The point is, we're making a runtime decision about how our code should behave based on knowledge of where the code has been deployed.
This is an antipattern! Don't do it!
Why Not?
This is not an article about configuration management. The lesson I want you to take from this article is NOT "don't hard-code my config values and group them by environment" (although you shouldn't). Instead I'll be using this as a specific case to illustrate more general concepts about application contracts and abstractions, and especially the direction that knowledge flows within your applications.
The problem with this hard-coding-and-grouping method is that it requires your application to have knowledge of where it's been deployed. If you decide to add another deployment environment (say, test or uat), you'll need to come back to your application code and handle that case. If you want to change just one variable for a specific use case, you'll need to add a special case or remember to change it back when you're done. You'll need to ensure that the rather arbitrary environment names stay consistent over time. All of these problems occur because you're encoding institutional and operational decisions into runtime behavior.
That's bad.
A Clean Contract
The code you write shouldn't have any knowledge about who or what is using it. It should clearly describe what it needs in order to do its job, and as long as the consuming entity provides those elements, the code should run without exception. This is known as the code's contract.
A clean contract is one that makes all its requirements explicit and consistent. A function with declared arguments and return value has a clean contract. By providing the inputs to the function, you'll get the documented output. If that function relies implicitly on some external service being available, or some other variable being in scope, the contract starts to get muddy.
This idea can be expanded outward to classes, modules, and entire applications. The contract is the surface area of the code in question. It defines what the consuming code needs to provide and what it can expect to receive in return, with the understanding that all the implementation details within the invoked code can be safely ignored by the consuming code.
Knowledge Should Flow in One Direction
So the consuming code should only have knowledge of the invoked code's contract, not its internals. And the invoked code should only know the values provided to fulfill its contract, with no knowledge of what provided them.
As you compose your classes and modules into ever larger systems and apply these rules thoughtfully, a pattern starts to emerge. A class or set of classes forms at the outer layer of your application and serves as the interaction interface for the application. That layer invokes some classes to perform some business logic. The interaction layer knows of the business layer's contract, but the business layer does not know anything about how it's being invoked. The business layer in turn may invoke other classes that contain lower-level domain logic. Similarly, the business layer knows the contract of the domain classes, but the domain classes don't know anything about how they're being invoked.
In other words, knowledge in your application flows on one direction through these layers. Any layer may have knowledge of those below it, but no layer may have knowledge of those above.
This system is known in various forms as Layered Architecture, Hexagonal (aka Port and Adapters) Architecture, or Onion Architecture. These are different approaches to organizing the concerns of your application, but they all organize it roughly in order of what will change most frequently (top/outer layers) to what will change least frequently (bottom/inner layers). Modules may depend on other modules from within their own layer, or lower/inner layers, but may NOT depend implicitly or explicitly on modules from outer/higher layers.
This is a mindset that can be hard to internalize. When you're trying to solve a problem, ship a feature, or fix a bug, it's easy to think of all the code as fair game to reach your desired end state. Although you are the omniscient creator of your application, you must use that omniscience to create systems of components who require as little knowlege of each other as possible. This is refered to as Separation of Concerns.
Infrastructure is the top/outer layer
But let's get back to our question of how to manage environment variables and configuration values.
The onion/hex/layered diagrams vary in how or whether they address infrastructure, but for our purposes in this conversation, infrastructure is the outermost layer. You may not think about it, but infrastructure changes multiple times per day. You're developing locally, you push to to a ci/testing environment, which deploys to a staging environment, which eventually deploys to production.
With all of this variability, your application needs to expose a clean contract to the environment in which it runs, and should not require any specific knowledge of that environment. A simple change that improves things dramatically is just to use environment values directly. We'll improve on this solution shortly, but let's start with simplicity for now.
const DATABASE_URL = process.env.DATABASE_URLSo how is that example better than our original?
The new and improved version exposes an outward contract that any environment may adhere to, while the original requires the application logic to have knowledge of the environment.
In the improved example, we are defining a requirement that must be met as part of the contract in order to run the code. When running the application, an environment variable must be defined that points to our database. This is the same as defining the arguments for a function. You're defining how the function may be used, and it's up to the consuming code to provide the correct arguments.
In the original example, if you create a new environment with a different URL for the database, you need to update your code with a reference to that new environment. That's breaking our rule about information flow. The code has to know where it's being deployed in order to do its job. It's requiring knowledge of the layer that sits outside of it. Again, that's bad.
Start by Defining Responsibility
So how do we compose our applications with an eye towards clean contracts and unidirectional information flow?
Learn to draw boundaries around the responsibilities of your system.
Your job as a software developer is to look at a large problem, break it into small problems, and design a system that can solve those small problems in order to arrive at the solution to the large problem.
Once you draw those boundaries around the smaller problems, determine what information should exist within each of those boundaries.
ONLY after you'e determined which information needs to exist where, should you decide specifically which information should cross the boundaries and how.
In the case of our environment variables, the boundary in question is between the deployed environment and the application code. Let's say in our application that we require two values to be set, an environment name, and a database url.
The environment is responsible for defining the values. The environment name could be test, prod, staging, qa, uat, dev-local, etc. The application code shouldn't have to keep track of where it's being deployed.
The database URL is similarly unconstrained. We could connect a locally running dev version of the application to the database running in our deployed staging environment if we wanted to, and the application should be none the wiser. (there could be infrastructure reasons that make this difficult or unwise, but those difficulties should be related to network topology and the like, rather than code logic.)

The application just requires opaque variable for both of these values. The app knows that the environment has a name and may log that value or display it in a UI somewhere, but it shouldn't be basing logical decisions on the literal value of the variable. That's not the app's responsibility and it would violate the direction of knowledge flow.
Likewise the app should never actually have to know the value of DB_URL. As long as a connectable string is provided by the environment, the application can pass it around freely without ever knowing its value.
Responsibility Leads to Abstraction
Knowing our division of responsibility, we can now look at how to define the abstraction that keeps that division intact, while providing the correct movement of information.
Every language has some method of accessing the environment variables in the running process. In JavaScript (specifically Node), that's process.env. In Ruby it's ENV, in Python it's os.environ.
Here in our first iteration, we're using a very simple abstraction, one that's basically given to us for free. We're defining a known list of environment variables which must be defined in order to run the application. That is, our application expects ENV_NAME, DB_URL, etc. to be defined at runtime. The presence of these two environment variables is part of the environment's contract with the application.
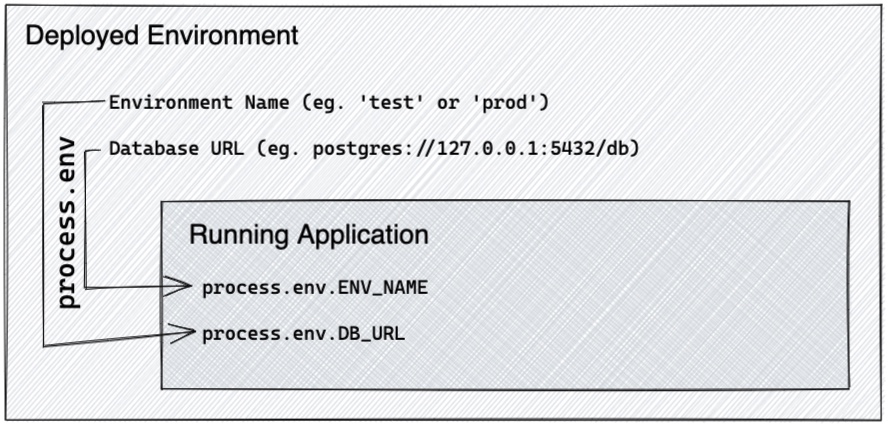
This really improves things on the environment side, compared to our original hard-coding-and-grouping method. We no longer have implicit constraints on the environment name imposed by the application, and we are free to alter individual values in the configuration without altering source code.
However, I don't like directly accessing process.env (or its analogues) within the application, for three reasons:
1) It's too blunt of a tool. Inside the application, we don't actually want to know aaallll of the environment variables. To see what I mean, type env at your terminal prompt and see how many environment variables exist at any given time.
2) The contract is still implicit. There's no canonical place to consult for which environment variables need to be defined when running the app.
3) process.env is globally available in your application code and it's mutable. Any part of your application can not only read it, but change it. That means you have NO guarantees when you access a value within your application that it's the same value that you started the app with. At its worst, this can encourage devs to start using process.env as a sort of global state object. Believe me when I tell you this is maddening to reason about and debug.
So in our application code, we want to create a more focused abstraction for configuration management. It will
- extract only the values that we define as part of the startup contract of our application
- make that contract explicit
- guarantee that values cannot be changed within the app.
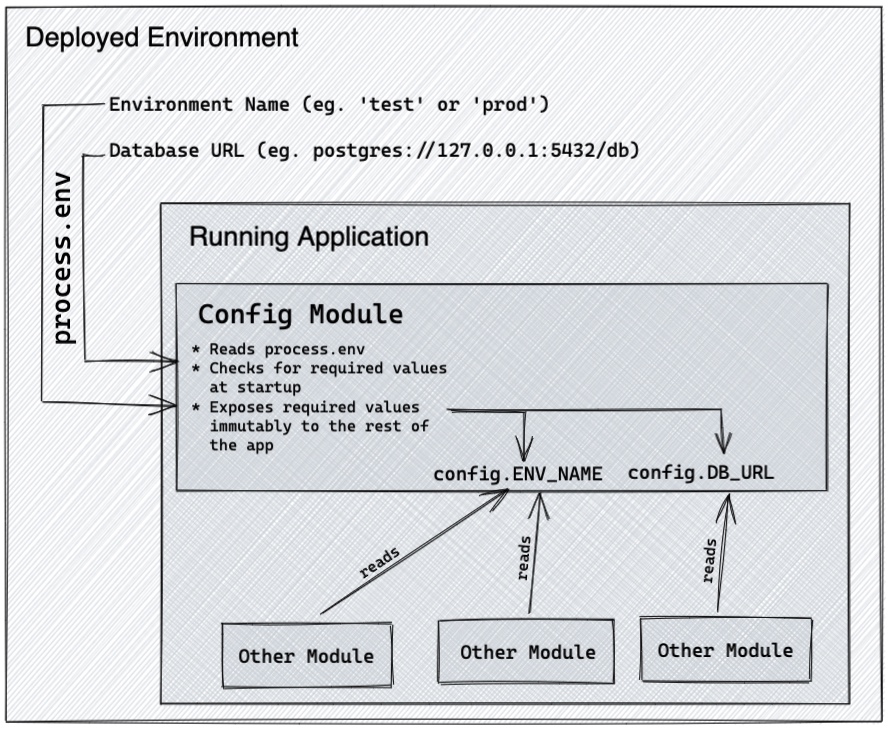
Now we have a dedicated config object, whose interface (aka abstraction) is more tailored to our needs. A very minimal implementation might look like this:
// define which values are required at startup
const REQUIRED_VALUES = [
'ENVIRONMENT_NAME',
'DATABASE_URL'
]
// Extract only the values we want for our app configuration,
// and throw an error if any are missing
const config = {}
REQUIRED_VALUES.forEach(varName => {
const value = process.env[varName]
if (value === undefined) {
throw new Error(`missing environment variable: ${varName}`)
}
config[varName] = value
})
// disallow any changes to object properties
Object.freeze(config)
// can be imported and read anywhere in the app
export default config
This implementation provides an allowed-list of only the environment values that we need, and it ensures that they won't be changed anywhere in the application. It will throw an explicit error at startup if any of those values are missing. And it could easily be enhanced to provide alternative means for getting configuration values into your application (for instance, a .env file or arguments to the startup command)
By creating a module whose defined responsibility is configuration management, we've taken an implicit contract (the environment variables made available on process.env) and made it explicit. The config module is now responsible for defining the application's external contract with regard to configuration: which values are required, how they can be passed in, how they are accessed in the application, and what happens if they are missing.
The final step if you are working in a team environment would probably be to add a linter rule that disallows accessing process.env directly. process.env is an easy tool that people reach for when they're in a hurry. However, it circumvents the contract that we've defined. If direct calls to process.env start proliferating through the codebase, our shiny new config module quickly falls into disuse and disrepair.
Defining Responsibility and Abstraction Leads to Testable Behavior
Defining responsibility and abstraction makes it possible to concretely define the behavior of your application's components. A concrete definition of behavior makes your components easily testable. I cover this in detail in my course Test Like a Tech Lead.
For instance, we can describe the behavior of our config module thusly:
Given defined environment variables
ENV_NAMEandDB_URL, when the config module is initialized, then it should expose read-only properties with those values
It's not a long leap to go from this statement into your testing framework of choice.
Behavior is the concretion to your abstraction. Where abstraction can be described, behavior can be evaluated for correctness. That evaluation becomes a test case.
That is to say, learning to think in abstractions teaches you to write testable code.
Previously:
Getting Beyond DRY